Impact of Tangible Cost Asset (TCA) Accounting on Electronic Recordkeeping Practices
SAGESSE VOLUME VII WINTER 2022 – AN ARMA CANADA PUBLICATION
by Bruce Miller, MBA, IGP
Introduction
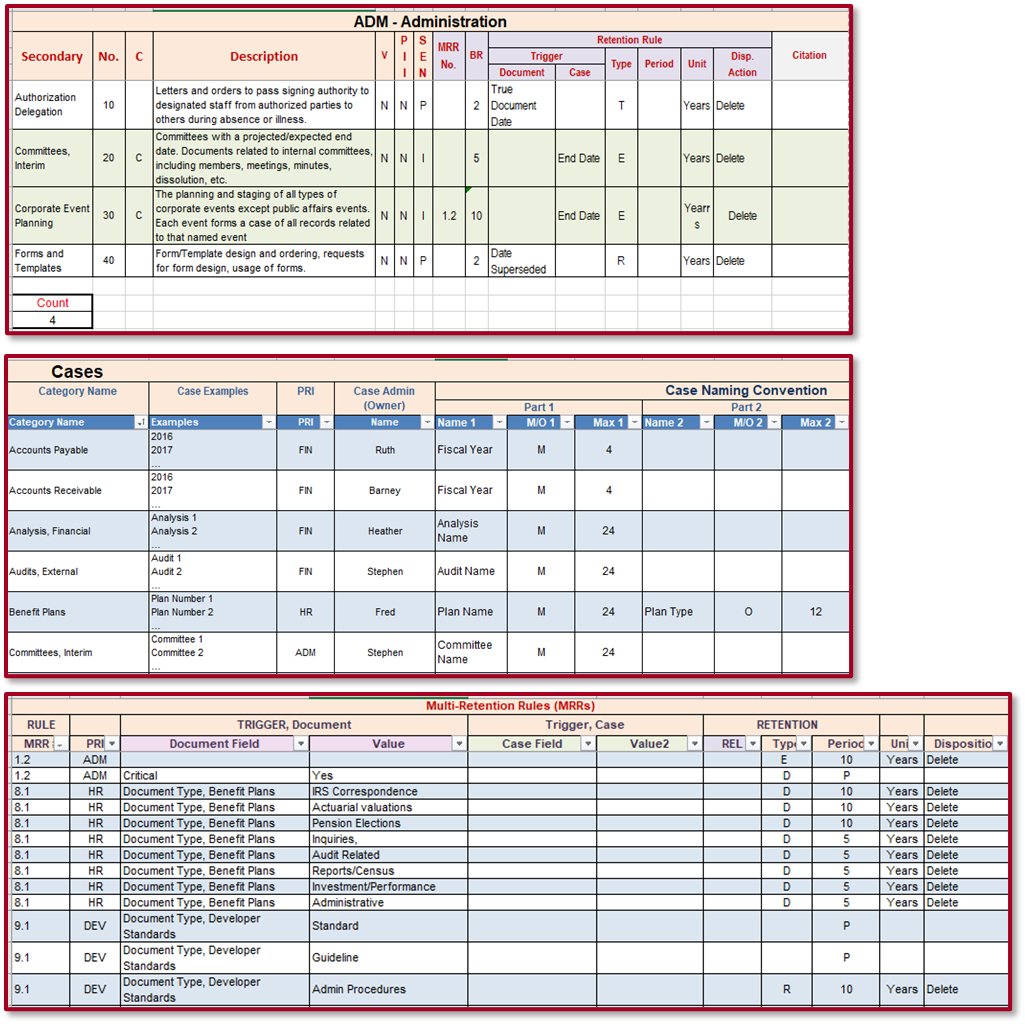
The purpose of this report is to document specific changes in recordkeeping practices that will be required for a municipality that has fully implemented TCA (Tangible Capital Asset) accounting practices. The changes in recordkeeping will occur in the following areas:
- The procedures used to create, identify (label), and file records in physical (paper) form will change.
- The procedures used to create, identify (declare) electronic records within a modern EDRMS (Electronic Document & Records Management System) system will change.
- The underlying Retention Schedule (File Plan). There are structural changes required in the retention rules within the schedule.
- The EDRMS must present asset data lists to the end users to support proper TCA recordkeeping.
We will assume that all municipalities should/will incorporate these recordkeeping changes, even if they have not yet fully adopted TCA accounting methods, as we assume they will eventually be adopting TCA.
We are assuming that TCA accounting practices are to be applied to a system for managing electronic records. For the purpose of this report, we will assume the EDRMS will be RBR (Rules-Based Recordkeeping) capable.
Definitions
Asset An individual, indivisible asset. Also sometimes referred to as a component.
Asset Class A set of assets forming a greater whole. For example, Roads is an asset class, comprising all the assets of Roads.
CAC Capital Asset Code (CAC). Unique code or identifier that identifies a particular asset. Can be alpha-numeric or numeric.
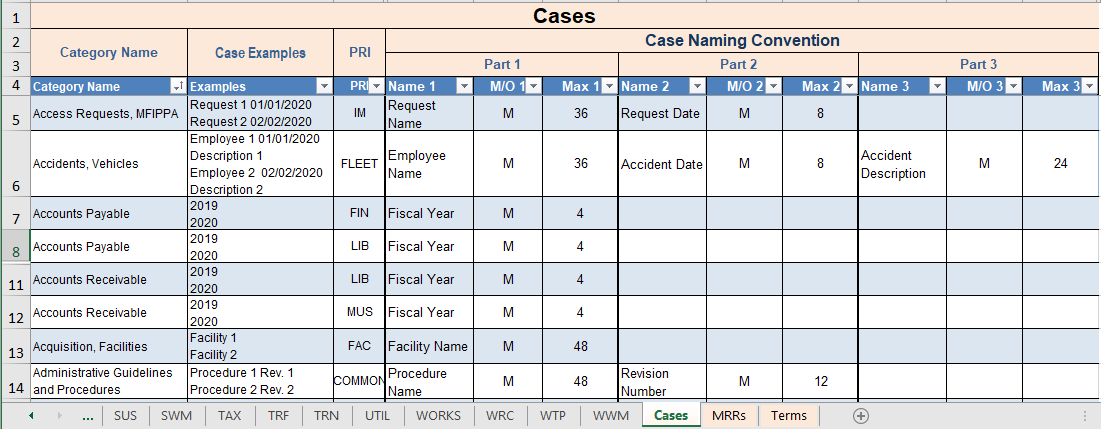
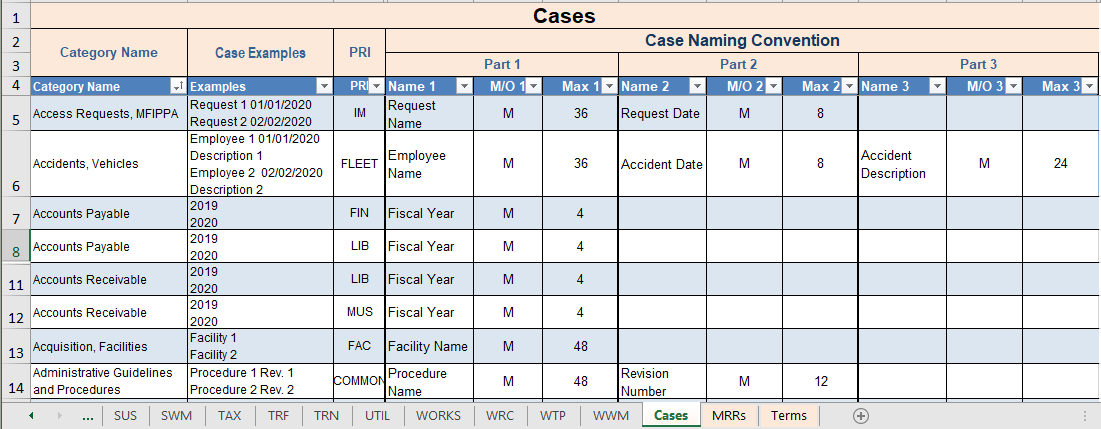
Case A set of related records, typically about a Person, Place, Event, or Thing. The set of records is not considered complete until some triggering event has taken place that defines the end of the business activity. For example, a company with 1,000 employees would typically have 1,000 “cases”, one for each employee that contains all the records for each particular employee over the duration of their employment. Each case contains all of the records for the activity (in this example the employment of the employee), from the beginning of the activity (start of employment) to the end of the activity (termination of employment).
Case Category A file plan category containing related records about a business activity with a defined end date. Disposition is triggered by an event date that defines the end of the activity, such as “End of Useful Life” (A machine), or “Close of all Legal Matters” (A workplace Accident). For example, employee records might be eligible for disposition 3 years after termination of employment. All records within a case category reach disposition and are processed as a complete, intact group – they are never separated or processed as individual records. In many organizations, 50% or more of all business records are case records.
Category A node in the hierarchical file plan. Denotes a set of records of related activity, i.e. Travel Requisitions. All categories are linked via a child/parent relationship. Each category is designated either as a Case or Administrative category, and is enumerated or labelled with a unique category ID.
Classify The process whereby a document is assigned a category from the file plan (retention schedule). Classification is often part of the Declaration process and can be achieved by the user (manual), or by the system (RBR). Manual classification can be achieved explicitly (the user selects and assigns a category), or implicitly (by virtue of selecting a storage location such as a folder, that matches the subject of the document, and which bears the appropriate category for that document).
Component The smallest, indivisible portion of a linear asset. It cannot be further broken down into parts.
Declare Manage a document as a record. The document is presumed to meet the criteria of a business record, however it may not. A declared document is tracked by the EDRMS, is classified against the file plan, and is immutable (users cannot edit or delete it) to preserve its integrity. It can only be deleted via the formal disposition process.
Disposition As distinguished from Deletion. Formal, structured process of determining what happens to records at the end of their retention period. The process is human-initiated, and the decision as to what is destroyed/transferred is ultimately governed by an approved file plan (retention schedule). A records administrator provides oversight of the process. Approval from originating business units is typically sought prior to physical destruction, and a formal audit trail of disposition is maintained. Disposition yields (3) possible outcomes following the expiration of the retention period:
- Destroy
- Transfer to outside agency for permanent archival storage
- Unknown. Retain until disposition is known. Some possibilities:
- Held for legal review
- In Dispute
- Disposition simply not yet known or decided
ECM Enterprise Content Management (system). A platform for the management of unstructured documents and data. Examples include Microsoft SharePoint, IBM’s Content Manager, and OpenText’s Content Manager. Most ECM platforms have recordkeeping capabilities.
EDRMS (EDRMS). A business information system in which the records of an organization are created, captured, maintained, and disposed of. Such a system also ensures their preservation for evidential purposes, accurate and efficient updating, timely availability, and control of access to them only by authorized personnel. An EDRMS includes rules and procedures governing the storage, use, maintenance and disposition of records and/or information about records, and the tools and mechanisms used to implement these rules.
An EDRMS delivers specified recordkeeping controls. Most systems can manage electronic and physical records. Many are comprised of general-purpose content management systems that deliver recordkeeping capability. Some are certified compliant with recordkeeping standards such as US DoD 5015.2 or ICA Module 2. An EDRMS can be configured to store exclusively records, however it will typically store all three of the following categories of items:
- Declared Records
- Non-Records
- Non-Declared (unmanaged) records
EOL End of Life. Trigger date that triggers the final retention period for the records. The date on which the asset reaches the end of its useful life. EOL can sometime represent the disposal date of the asset, where the disposal date exceeds the originally-projected asset EOL.
Linear Asset An asset with no defined starting or ending point, and multiple interconnected components, such as a buried pipeline, or systems of roadways. A linear asset must therefore be broken into manageable pieces, each of which will be considered an individual asset.
MACL Master Asset Class List. The list of all assets, each asset bearing an identifying code (CAC). This list is presumed to be stored in some corporate database system, such as an ERP (Enterprise Resource Planning) system. Examples of such systems may include SAP, JD Edwards, or Microsoft Dynamics. Any list of assets presented within the EDRMS is presumed to be derived from the MACL, either by duplicating the list, or by presenting the MACL within the EDRMS via a software integration between the EDRMS and the ERP system hosting the MACL.
Project A predetermined list of assets that have received budget approval for work to be carried out on the assets. Typically, a project is assigned a G/L code, and a date.
RBR (Rule-Based Recordkeeping). An automated method of selecting documents to manage as records by defining rules that the targeted documents must meet. Rules typically match documents based on Content Types and/or metadata field values, then declare the document as a record, and classify it against the file plan.
Retention Schedule Also known as a File Plan. The list of approved retention periods and disposition rules for each business activity or subject area within the organization. Typically a hierarchy of business functions broken into specific activities. Driven by legislative obligation (various laws and regulations that apply to the business), and operational corporate policies. Also identifies which records are vital.
TCA Tangible Capital Asset. An asset.
EDRMS
EDRMS is a blend of two core technologies (along with several optional additional technologies). The first is a modern ECM (Enterprise Content Management) platform (which used to be known as document management). This platform forms a digital repository for all electronic records, and provides for advanced searching by content and metadata, security control, version management, workflow automation, and collaboration such as multi-author document editing, and much more. The second technology is recordkeeping capability, often delivered as a set of features within the ECM itself or as a third-party product added to the content management platform.
The records retention schedule underpins both technologies. The retention schedule does more than just feed retention rules to the ECM platform-it actually greatly influences the configuration of the ECM itself. This is necessary for the recordkeeping component to do its job properly.
All modern EDRMS systems incorporate RBR (Rules-Based Recordkeeping) to some extent. RBR is an approach to electronic recordkeeping that automates the recordkeeping functions the end user would normally have to carry out. These functions include identifying which documents are records, when to declare documents as records, and how to classify the documents against the retention schedule. A full and proper EDRMS deployment that fully utilizes RBR capability automates all these end user recordkeeping functions. End users have absolutely no role to play in the declaration or classification of any records. They simply operate the system as an ordinary everyday ECM, without thinking about records management whatsoever. Thanks to RBR however, in the background documents are being declared as records and are being properly classified against the retention schedule, even if the user is blissfully unaware of this.
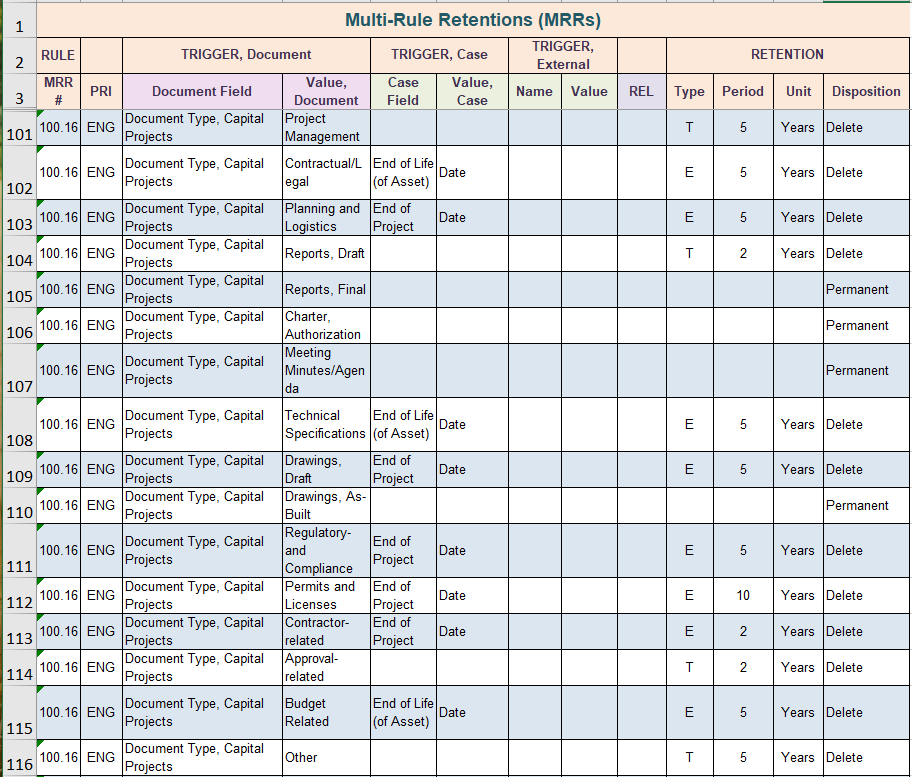
Modern electronic recordkeeping software can carry out retention and disposition in ways not previously available. Because the records are digital, we have more document-level information to deal with and we can leverage that information to do more granular, more sophisticated, and more flexible retention and disposition. For example, we can apply retention based on the value of documents, we can apply multiple retention rules to a single category, even different types of retention rules within the same category. The software has these amazing retention and disposition capabilities, however we have to tell it what we want it to do. And that’s the job of the retention schedule. If we know what the recordkeeping software is capable of in terms of retention and disposition, then we can write a retention schedule to take full advantage of these powerful new capabilities. A retention schedule that leverages these retention and disposition capabilities is referred to as a “software ready” retention schedule.
A software ready retention schedule is written with the assumption that it will be used within an EDRMS and will take full advantage of the advanced retention and disposition capabilities of the software. Any well-written software ready retention schedule can be used with any modern recordkeeping software, regardless of brand.
Figure 1 shows what a modern EDRMS looks like conceptually. There are three “layers” to an EDRMS:
The retention schedule The software ready retention schedule. This will be divided into case categories and administrative categories. On the left side are two administrative categories (operator rounds, and employee onboarding). On the right are two case categories (union grievances, and safety audits).
ECM structure Often referred to as “information architecture”, the ECM structure consists of all the so-called “libraries”, or places that documents can be stored. Different ECM products have different names for storage locations. Storage locations can be called libraries, folders, cabinets, etc. ECM structure also consists of the metadata, fields of information permanently stored with each document placed in each storage location. There is more to ECM structure than just libraries and metadata, including such things as versioning, security and collaboration, etc. But for now we’re only concerned with libraries and metadata.
RBR rules RBR rules refer to the rules created within the recordkeeping software to automate the recordkeeping processes, namely declaration (which documents are declared as records and when), and which retention rules in the retention schedule get applied to which locations in the ECM structure.
Done properly, the retention schedule massively impacts the ECM structure. Each category in the retention schedule translates to a library in the ECM structure. This library is where users will store documents for that particular category. Both the category and the library bear exactly the same name. Case categories require that the library be subdivided into “cases”, or containers, one for each case. This allows us to group records of each case together, separate from and independently of all other cases.
At the top of the pyramid lies the recordkeeping software and its RBR rules. This is where you define declaration rules such as “if library = “operator rounds” and approved = “yes” then declare”. Retention rules also get defined here, such as “if library = “operator rounds” retention equals true document date +5 years”. The rules need to know what the library names are, and what metadata it can work with.
As you can see, the retention schedule forms the base upon which the ECM is structured. This in turn allows the RBR rules to execute against that structure, as shown in figure 3.
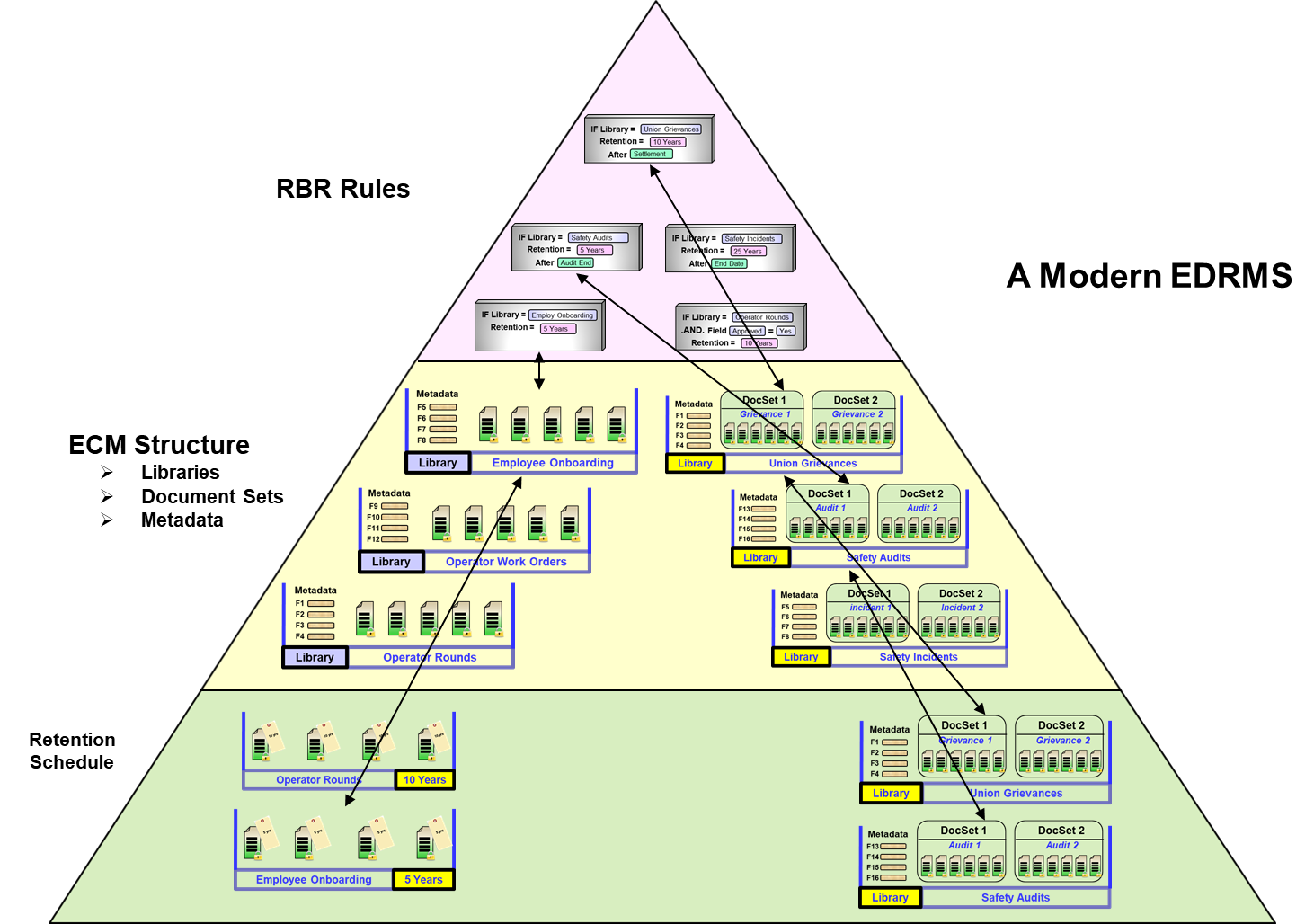
Figure 1 – A Modern EDRMS
Case Records
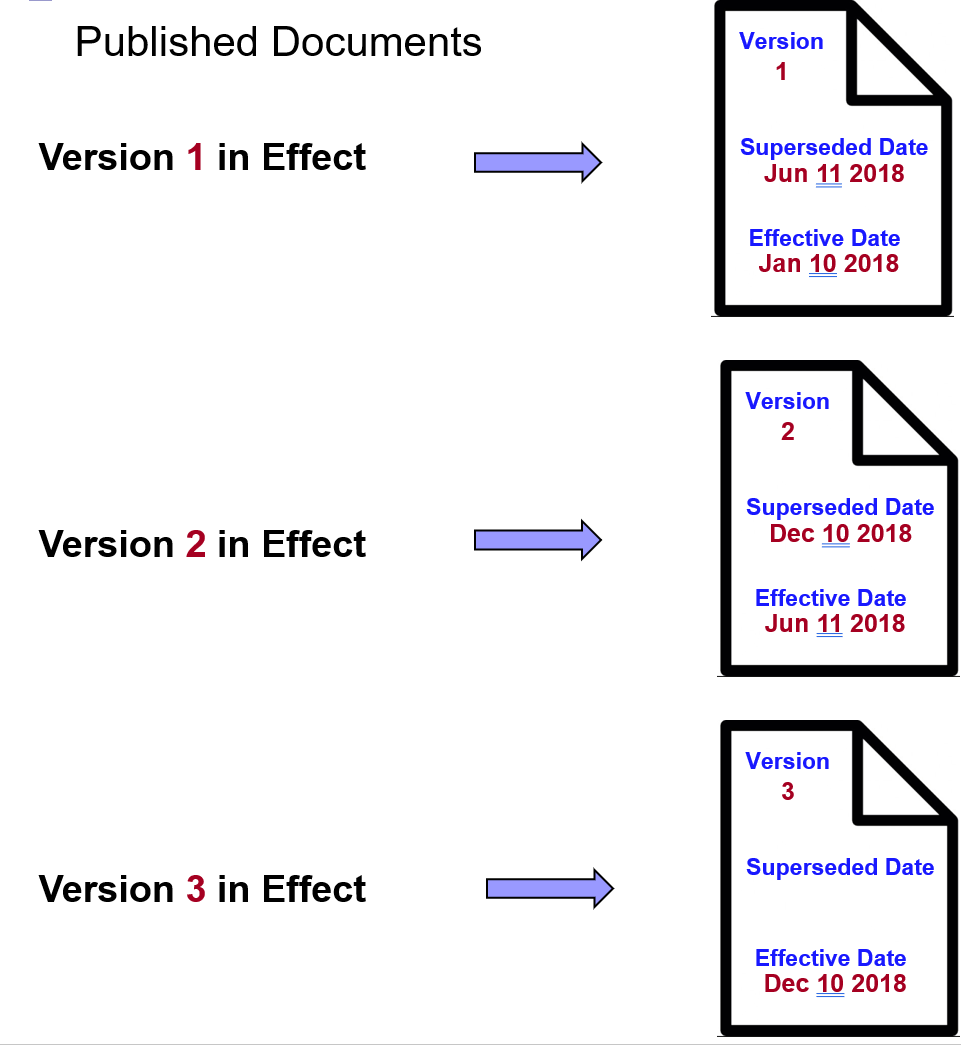
The retention schedule must differentiate between case and so-called “administrative” record categories. Each category in the retention schedule therefore is either a case category or an administrative category. In most organizations today, about 60% of all records belong to case categories. The best way to understand case records structure is with the help of an example. Suppose you have 1000 contracts in existence at any one time. Each contract has a contractor name, the contract value, an expiration date, a contract type, etc. This data will not change among all the documents in any given case. Each contract theoretically could have an expiration date different from those of all other contracts. All contracts would have a single retention rule similar to “keep five years after contract end date, then destroy”. Although there is only one single rule applied to all 1000 contracts, that single rule has 1000 different trigger dates, i.e. 1000 different expiry dates. The recordkeeping software must therefore track each of these 1000 dates.
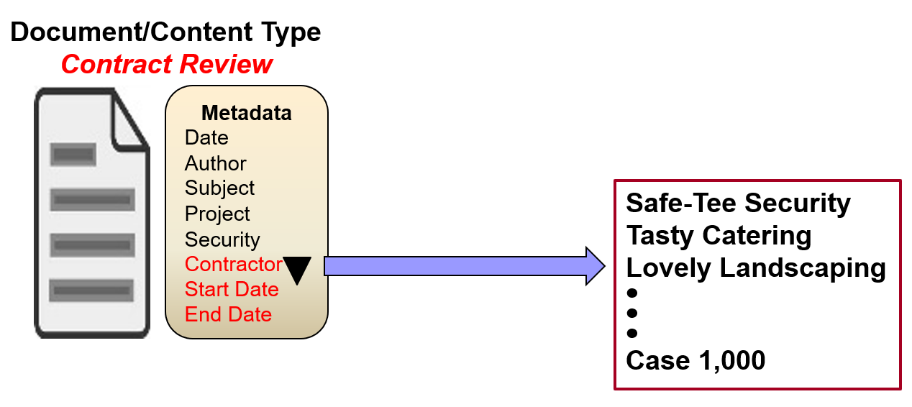
Let’s look at this from the perspective of an EDRMS end user. A user has a document related to a particular contract. The document may be an email suggesting several changes to the draft of the contract. The user must specify which of the 1000 contracts the document is related to. How is this accomplished? The user must have a way to choose from among the 1000 contracts. How this is done can vary among different ECM systems but the most common would be a simple drop-down list of all 1000 contracts, as shown in figure 2. Each contract has a unique name, and the user must select one of the 1000 contracts. The ECM will have a library known as “contracts”. That library will be further subdivided into 1000 case containers, each bearing a unique name of one of the 1000 contracts. This is a good example of how the retention schedule shapes the ECM structure. The two have to work in concert, and only then can the RBR rules be applied to the records within these libraries.

Figure 2 – Contract Selection
TCA Overview
Tangible capital assets (assets) are non-financial assets having physical substance that:
- Are held for use in the production or supply of goods and services for rental to others for administrative purposes or for the development, construction, maintenance or repair of other tangible capital assets;
- Have useful economic lives extending beyond an accounting period;
- Are used on a continuing basis; and
- Are not for resale in the ordinary course of operations
The diagram that follows shows typical municipal TCAs:
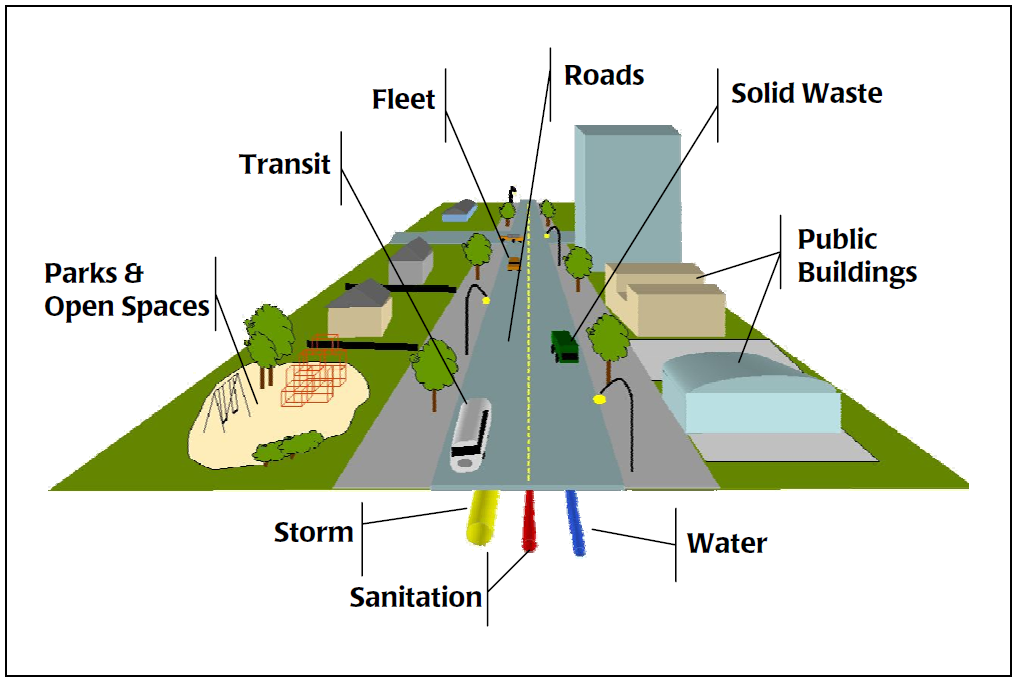
Figure 3 – Asset Classification
With the asset accounting approach, municipalities now:
- Identify each asset by class/category
- Identify a current and ongoing value of that asset
- Continuously track the current value of each asset by tracking the funds and work invested in the asset each year.
The financial statements must now disclose, for each major category of asset and in total:
- Costs at the beginning and end of the period;
- Additions in the period;
- Disposals in the period;
- The amount of any write-downs in the period;
- The amount of amortization of costs of asset for the period;
- Accumulated amortization at the beginning and end of the period
- Net carrying amount at the beginning and end of the period.
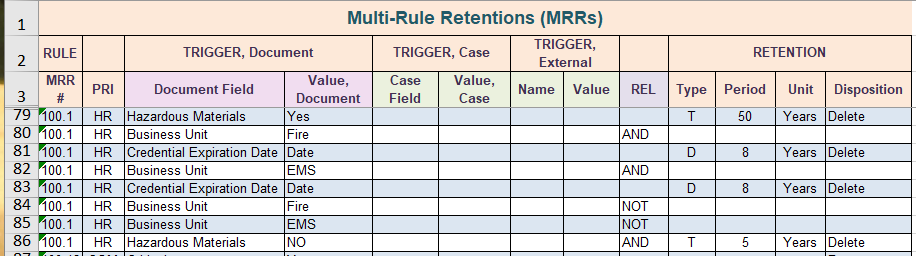
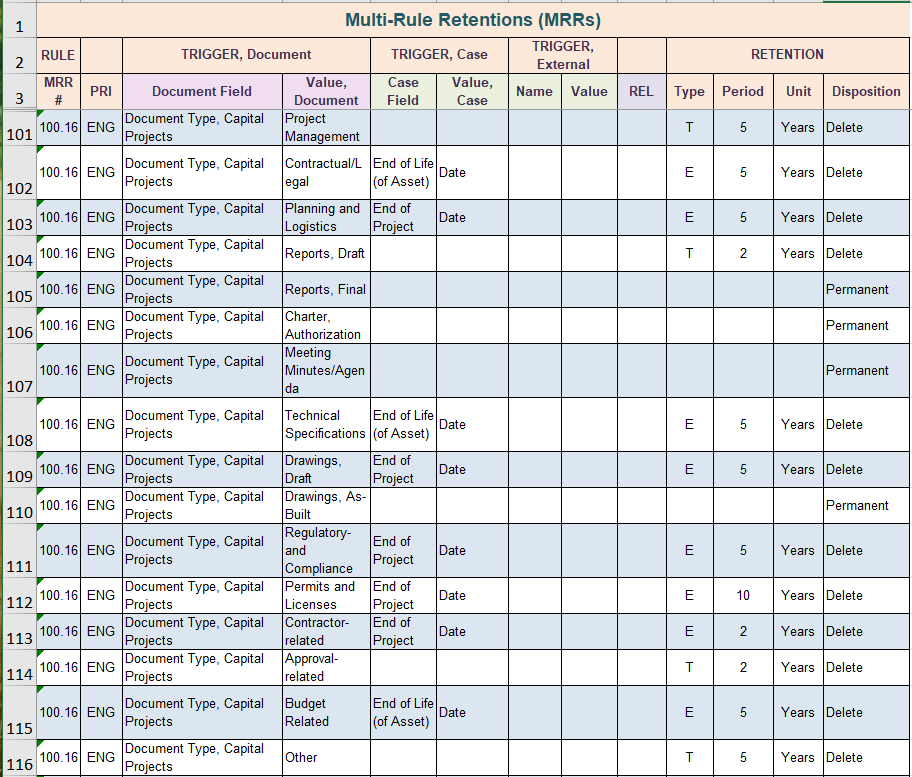
As shown in the table below, each of the assets has a cost assigned to it each year. Anything the municipality does to that asset that affects its value has to be tracked, so as to show an increase or decrease in its value. This means the Finance people need to associate work activities with each individual asset. This in turn means that the records generated by the activity, which support the work carried out on these assets, must also be associated with each individual asset.
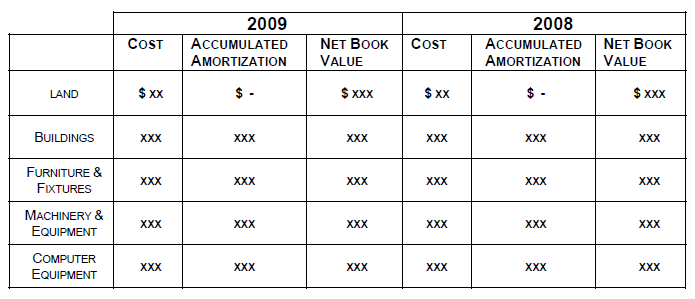
A typical Asset Inventory Sheet is shown in Appendix 2. A Property Record Card is shown in Appendix 3. These are typical of the documents used to record and track assets. These days, asset data, which is usually voluminous in nature, is recorded in modern ERP (Enterprise Resource Planning) systems.
Recordkeeping Implications
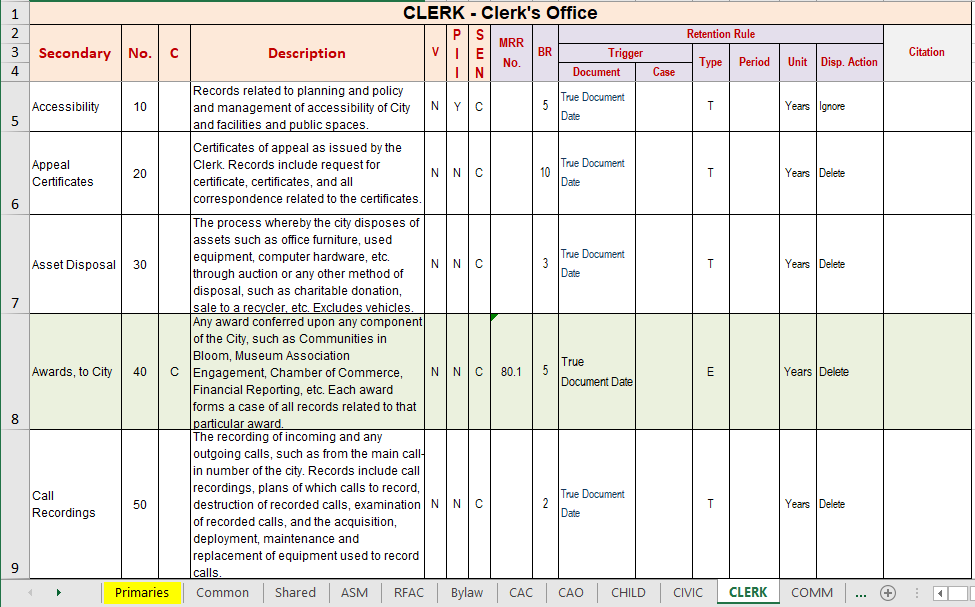
The following are the major impacts on recordkeeping as a result of TCA Accounting practices:
Asset Classification There must be a clear means of identifying (naming) Tangible Capital Assets that recordkeeping is aware of.
TCA Records Identification There must be a means whereby a given record can be related to (associated with) an asset.
Retention Rule Structure The retention schedule rules must be structured in a certain way to accommodate appropriate retention for assets.
Asset List Synchronization The master list of assets must be synchronized with the corresponding list in the EDRMS.
EDRMS Configuration The host EDRMS must be configured with user selection lists and other metadata characteristics in order to support TCA recordkeeping.
Asset Types and Classification
Assets are loosely grouped into Infrastructure and Non-Infrastructure assets, as shown below:
Infrastructure
Roads
Facilities (buildings)
Waste and Storm Water Management (WSW)
Water Treatment and Distribution (WTD)
Parks and Playgrounds (sometimes referred to as Land Improvements)
Non-Infrastructure
Fleet
Equipment
Infrastructure assets can be considered to be those assets that are in, attached to, or represent improvements upon, the land (such as parks). Activities carried out upon these assets generate records that document these activities. In an asset setting, these documents (records) must be associated with each asset so the finance people can determine how much money was spent on a particular asset, and what impact that activity had on the asset. Furthermore, certain selected records need to be preserved for the life of that asset in order to support Finance’s claim as to the value of the asset.
It’s obviously too general simply to say “the asset”. A municipality would have a network of hundreds of miles/KM of roads, or several miles/KM of buried pipeline. These types of assets are referred to as Linear Assets. Under TCA rules, each asset is broken down into individual components, each of which are indivisible. These components are treated in isolation of each other component. It is important to understand how assets are divided up into components. It is a simple breakout of an asset into its components parts. Each municipality will have its own particular approach to the breakout of its assets – there is no single “right way” to define it. We will list some examples of typical breakouts.
Let’s start with Roads. How do we treat a large systems of roadways as an asset? We break it down into its component parts, as shown:

Figure 4 – Road Segmentation
Each road is named, in our case Road 1 and Road 2. The road is then divided into Segments, segments 1-4 as shown in our example. Each segment is then broken into individual components. Note for instance that Road 2 segment 2 (R2S2) has a concrete sidewalk, whereas Road 1 Segment 1 (R1S1) has a pavement sidewalk. TCA accounting needs to know this distinction, as it will place a lower value on the sidewalk for R1S1 compared to the sidewalk for R2S2. In addition, it tells us that a repair or maintenance will be required sooner on the sidewalk for R1S1 compared to the sidewalk for R2S2. This is the inherent benefit of TCA accounting – by breaking down a large, complex (and often aging) asset into individual components, the municipality can better understand and budget maintenance, and make better decisions based on an accurate valuation of the assets.
As mentioned earlier, different municipalities will have somewhat different approaches to how they break down an asset, what they name the individual pieces, and how many levels they choose to utilize in this breakdown. Let’s take Facilities as an example. Below are shown four facilities:
Building 1 (a stadium)
Building 2 (a recreation centre)
Building 3 (a fire hall)
Building 4 (an animal shelter)
A facility may be broken down as follows:
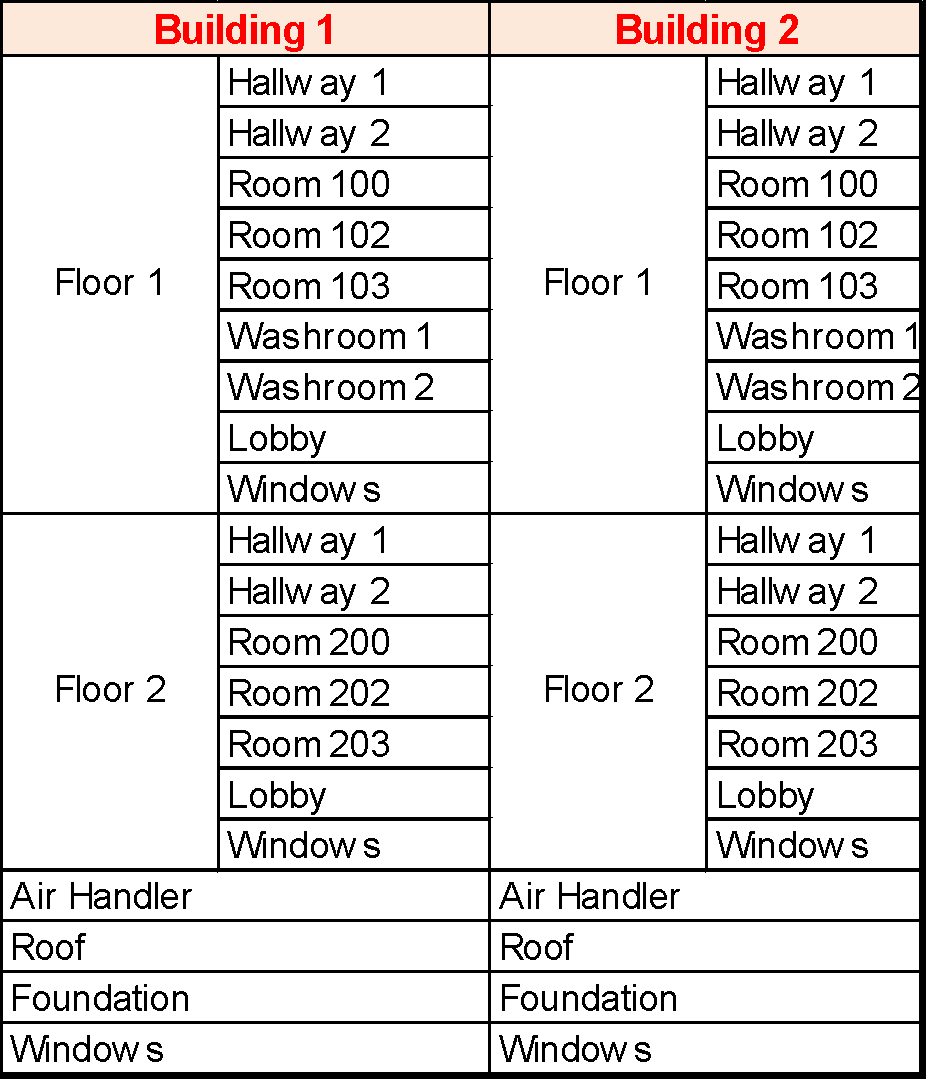
Each of the two facilities (buildings) has been broken down into its component parts. Suppose the washrooms in both buildings 1 and 2 are renovated, via a single contract. That means that four washrooms (2 in each building) were renovated. This renovation activity affected 4 individual assets, i.e. the four washrooms. The records generated by the specifications for the work, the contract selection and award, the construction, and payment, all relate to the following four assets:
Building 1 washroom 1
Building 1 washroom 2
Building 2 washroom 1
Building 2 washroom 2
MACL Synchronization
When an EDRMS user declares an asset-related document by placing it into the EDRMS as a record, they must have a means of selecting the appropriate asset, such as:
Vehicle X from the list of vehicles
Pump X from the list of Water Distribution Pumps
Road segment X from the list of road segments
This list must obviously be presented within the EDRMS. It must also be current (up to date) with the MACL. Remember that the MACL “lives” in the ERP system, not the EDRMS. If the MACL is extracted from the ERP system and displayed in the EDRMS via a custom integration between the EDRMS and the ERP system hosting the MACL, the EDRMS is not storing a duplicate of the MACL. Inside the EDRMS, the EDRMS is merely querying the ERP system and presenting the MACL. If, however the MACL is stored in the EDRMS as a duplicate, the MACL and the duplicate list in the EDRMS will eventually differ, as changes are made to the MACL. In this case, there must be a means by which the MACL and the EDRMS can be synchronized, either continuously in real time, or periodically (e.g. every 24 hours). This means that:
- When a new CAC is added to the MACL, the EDRMS asset list must be updated.
- When Finance changes the EOL of an asset, the Records Manager must be made aware of it so they can change the trigger date in the asset’s retention rule.
In a small municipality with limited IT resources, this synchronization will have to occur manually, i.e. Finance and the Records Manager must keep each other informed of changes as they occur. If the Master Asset Class List and the EDRMS fall out of sync over time, the entire recordkeeping process is no longer TCA-compliant. In a larger municipality with a larger MACL, and more IT resources, there are many ways to build custom software integration solutions that will automatically update the retention rules automatically as a result of changes to the MACL.
The MACL is the master list – the authoritative list of assets. Put another way, the retention schedule and the ECM Asset Lists (used for end user selection) are both subservient to the MACL. The retention schedule and the ECM Asset List must somehow keep up with changes in the MACL. A “change” means an addition to, a deletion from, or a modification to an existing MACL entry. This sets up a three-way synchronization challenge as illustrated below:

Whenever a change is made to the MACL, both the Asset List (in the ECM), and Retention Schedule (Assets IDs and EOLs) must be updated accordingly with the changes. Worse still, there is a strong interdependence between the retention schedule and the SharePoint Asset Lists. The RBR rules contain explicit field values for assets. Therefore, the RBR rules can only work if the Asset field values are being presented in the ECM
Every time the MACL changes, these changes need to be communicated to IT so they can update the ECM Asset List, and to Records Management so they can update the retention categories, including any changes in the EOLs. This could represent a great deal of manual data entry. In a larger municipality this could approach a full-time job just for the data entry. The solution is a custom integration between the ERP system and the EDRMS as illustrated below:

This integration could take the form of a custom integration that runs in real time, or periodically, (e.g. at midnight each night). The MACL could be an asset management application such as WorkTech, or it could be as simple as a spreadsheet. Each time there is an asset change, the integration software would take the actions as shown in the table below:

Physical Records
How would TCA recordkeeping be handled with physical (paper) records)? The same approach as used in electronic would have to be used for paper:
- Each paper document would have to be filed in a folder with same labelling as called for in the electronic system. Each label would have to bear a CAC number, drawn from the Master Asset List.
- The records would have to be marked with the appropriate TCAS status. This means TCAS records must be physically segregated from the remaining records in the category.
The paper system would in this case follow the electronic. The electronic system is presenting the choices to the end user, who will have to follow through and label the documents and folders appropriately. With physical records, users will need access to paper copies of the following lists in order to properly classify (file) records:
Retention Schedule
Master Asset Class List
Project List (for project cases)
The retention schedule will generally not change very often, however the Master Asset Class List and the Project list could change quite frequently. If this is the case, it would be best if the users used the computer just to look up appropriate values in these lists, instead of having to rely on paper copies that could quickly get out of date.
Using TCA
Appendix 1 shows a high-level view of how records are handled in an asset-compliant setting. If the record being declared describes an activity that has affected a specific named asset, then the process shown on the right-hand side of the diagram is applied. We refer to this as an ARM (Asset Repair & Maintenance) record. If the record is not dealing with a repair or maintenance, then there are three possibilities on the left-hand side of the diagram as shown:
Construction of New Asset Building of a new asset or group of assets. This would only apply to assets that have to be built, i.e. roads, facilities, storm drains, and land improvements. It does not apply to assets that have to be acquired, such as equipment or fleet. The user has to select the secondary ACS (Asset Construction), specify the asset class to which the activity pertains, then select a case project. A case project will typically be a capital-funded construction project. All construction projects are cases.
Planning/Management Activities related to the general planning and overall management of the assets, such as long-term plans and forecasts, estimates for future funding, etc. The user has to select the secondary APM (Asset Planning & Management), specify the asset class to which the activity pertains, then select a specific named asset.
Operations Regular operation of the assets, such as snow clearing (roads), window cleaning and janitorial services (buildings/facilities), leasing (land, buildings), inspections, etc. The user has to select the secondary AOP (Asset Operations), specify the asset class to which the activity pertains, then select a specific named asset.
Suppose a record is about a repair on a specific asset – a road segment for example. The repair applies to a specific named asset (the road segment), so the right-hand side of the diagram applies. It is an ARM record. First the user must select the asset class, in this case Roads. Then, from within the asset class of Roads, they have to select a specific (named) asset, for instance Maple Street Segment 2. It’s possible that for some reason, the asset is not available in the selection list. If so, the software will have to notify the Records Manager of the need for this asset, and the user will have to wait and try again later.
Assuming the asset appears in the list, the user selects it. If the user happens to be a designated administrative user, the software can ask explicitly if this record indicates activity that results in a betterment of the asset. This would apply to very few users who are entrusted with the knowledge and motivation to answer this question appropriately. We will assume however that most of the time, this is a non-privileged user not trained to properly answer the question.
Now the user must select a document type, such as:
Invoice
Drawing, As-Built
Drawing, Final
Specifications
Timesheet
etc.
The Document Type is a mandatory document metadata field. Each of these document types is defined in advance and presented to the user as a limited selection – they have to identify the appropriate document type. The definition of each document type specifies whether the document type represents TCAS documents, or not (this is an internal system attribute or field). By selecting the appropriate document type therefore, we now know if the document is a TCAS record or not. If TCAS, the EDRMS will assign a retention period of EOL + X years. If the document is non-TCAS, it will be assigned a retention period of X years.
Suppose however the record is a plan specifying which roads to repair in the coming summer months. This document does not affect a specific (named) asset. It is therefore an APM (Asset Planning & Management) record. The user will go to the APM section of the file plan, then select an asset class, in this case Roads. The record’s classification is “APM-Roads”. Roads is the primary level, Planning & Management is the secondary level. The retention period will be (typically) X years.
A record would follow a similar process if it were about routine operations of an asset. Suppose the document was a plan for road snow clearing. This does not affect the asset itself – it is purely an operational activity. The user would go to the ROADS section of the file plan, then select the activity “Operations”. The record’s classification is “Roads – Operations”. Roads is the primary level, Operations is the secondary level. The retention period will be (typically) X years.
Appendix 1
TCA Usage

Appendix 2
Asset Inventory Sheet

Appendix 3
Property Record Card

About the Author
Bruce Miller, MBA, IGP is a world leading expert on electronic recordkeeping. He is an independent consultant, an author, and an educator. Widely regarded as the inventor of modern electronic recordkeeping software, he pioneered the world’s first commercial electronic recordkeeping software in 1989. In 1997 he achieved the world’s first e-Records software certification against the US DoD 5015.2-STD standard, and has since presided over several successful software certifications. In 1999 he developed the world’s first e-Records software engine for business software. That year he received ARMA Canada’s National Capital Region’s Ted Ferrier Award of Excellence for his contribution to the field of records management. Bruce’s software was the first technology in the world to be certified against the revised 5015.2 June 2002 standard. In 2002 his company was acquired by IBM, where he served for three years as IBM’s global e-Records Strategy and Business Development Executive. At IBM he was honoured as a Technical Leader, one of only 439 out of 360,000 IBM employees. Mr. Miller is the recipient of the prestigious 2003 Emmett Leahy Award, considered the highest international recognition given to professionals in the field of information and records management. His book “Managing Records in Microsoft SharePoint 2010” was an ARMA best seller, and the second edition was released in October 2015. Bruce holds a Diploma in Electronics Engineering Technology, a Masters in Business Administration from Queen’s University, and is a certified Information Governance Professional. Learn more about Bruce and his consulting practice at https://www.rimtechconsulting.com.